44 keras reuters dataset labels
GitHub - kk7nc/Text_Classification: Text Classification … Random projection or random feature is a dimensionality reduction technique mostly used for very large volume dataset or very high dimensional feature space. Text and document, especially with weighted feature extraction, can contain a huge number of underlying features. Many researchers addressed Random Projection for text data for text mining, text classification and/or … Datasets in Keras - GeeksforGeeks 07.07.2020 · CIFAR10 (classification of 10 image labels): This dataset contains 10 different categories of images which are widely used in image classification tasks. It consists The dataset is divided into five training batches , each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches ...
tf.keras.utils.text_dataset_from_directory | TensorFlow v2.9.1 Generates a tf.data.Dataset from text files in a directory. Install Learn Introduction New to TensorFlow? TensorFlow The core open source ML library For JavaScript TensorFlow.js for ML using JavaScript For Mobile & Edge TensorFlow Lite for mobile and edge devices For Production TensorFlow Extended for end-to-end ML components API TensorFlow (v2.9.1) r1.15 …
Keras reuters dataset labels
martin-thoma.com › nlp-reutersThe Reuters Dataset · Martin Thoma Jul 27, 2017 · Reuters is a benchmark dataset for document classification. To be more precise, it is a multi-class (e.g. there are multiple classes), multi-label (e.g. each document can belong to many classes) dataset. It has 90 classes, 7769 training documents and 3019 testing documents. It is the ModApte (R(90)) subest of the Reuters-21578 benchmark . Keras - Model Compilation - tutorialspoint.com y_true − true labels as tensors. y_pred − prediction with same shape as y_true. Import the losses module before using loss function as specified below −. from keras import losses Optimizer. In machine learning, Optimization is an important process which optimize the input weights by comparing the prediction and the loss function. Keras provides quite a few optimizer as a … › datasets-in-kerasDatasets in Keras - GeeksforGeeks Jul 07, 2020 · CIFAR10 (classification of 10 image labels): This dataset contains 10 different categories of images which are widely used in image classification tasks. It consists The dataset is divided into five training batches , each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class.
Keras reuters dataset labels. › api_docs › pythontf.keras.utils.text_dataset_from_directory | TensorFlow v2.9.1 Overview; LogicalDevice; LogicalDeviceConfiguration; PhysicalDevice; experimental_connect_to_cluster; experimental_connect_to_host; experimental_functions_run_eagerly The Reuters Dataset · Martin Thoma 27.07.2017 · Reuters is a benchmark dataset for document classification. To be more precise, it is a multi-class (e.g. there are multiple classes), multi-label (e.g. each document can belong to many classes) dataset. It has 90 classes, 7769 training documents and 3019 testing documents. It is the ModApte (R(90 … › datasets-in-kerasDatasets in Keras - GeeksforGeeks Jul 07, 2020 · CIFAR10 (classification of 10 image labels): This dataset contains 10 different categories of images which are widely used in image classification tasks. It consists The dataset is divided into five training batches , each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. Keras - Model Compilation - tutorialspoint.com y_true − true labels as tensors. y_pred − prediction with same shape as y_true. Import the losses module before using loss function as specified below −. from keras import losses Optimizer. In machine learning, Optimization is an important process which optimize the input weights by comparing the prediction and the loss function. Keras provides quite a few optimizer as a …
martin-thoma.com › nlp-reutersThe Reuters Dataset · Martin Thoma Jul 27, 2017 · Reuters is a benchmark dataset for document classification. To be more precise, it is a multi-class (e.g. there are multiple classes), multi-label (e.g. each document can belong to many classes) dataset. It has 90 classes, 7769 training documents and 3019 testing documents. It is the ModApte (R(90)) subest of the Reuters-21578 benchmark .
Nlp News Dataset - NLP Practicioner
![[Keras] 뉴스 기사 토픽 분류로 보는 다중 분류(multi-classification)](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https:%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F994BEC3D5C2354770B)
[Keras] 뉴스 기사 토픽 분류로 보는 다중 분류(multi-classification)

Data Augmentation tasks using Keras for image data | by Ayman Shams | Medium
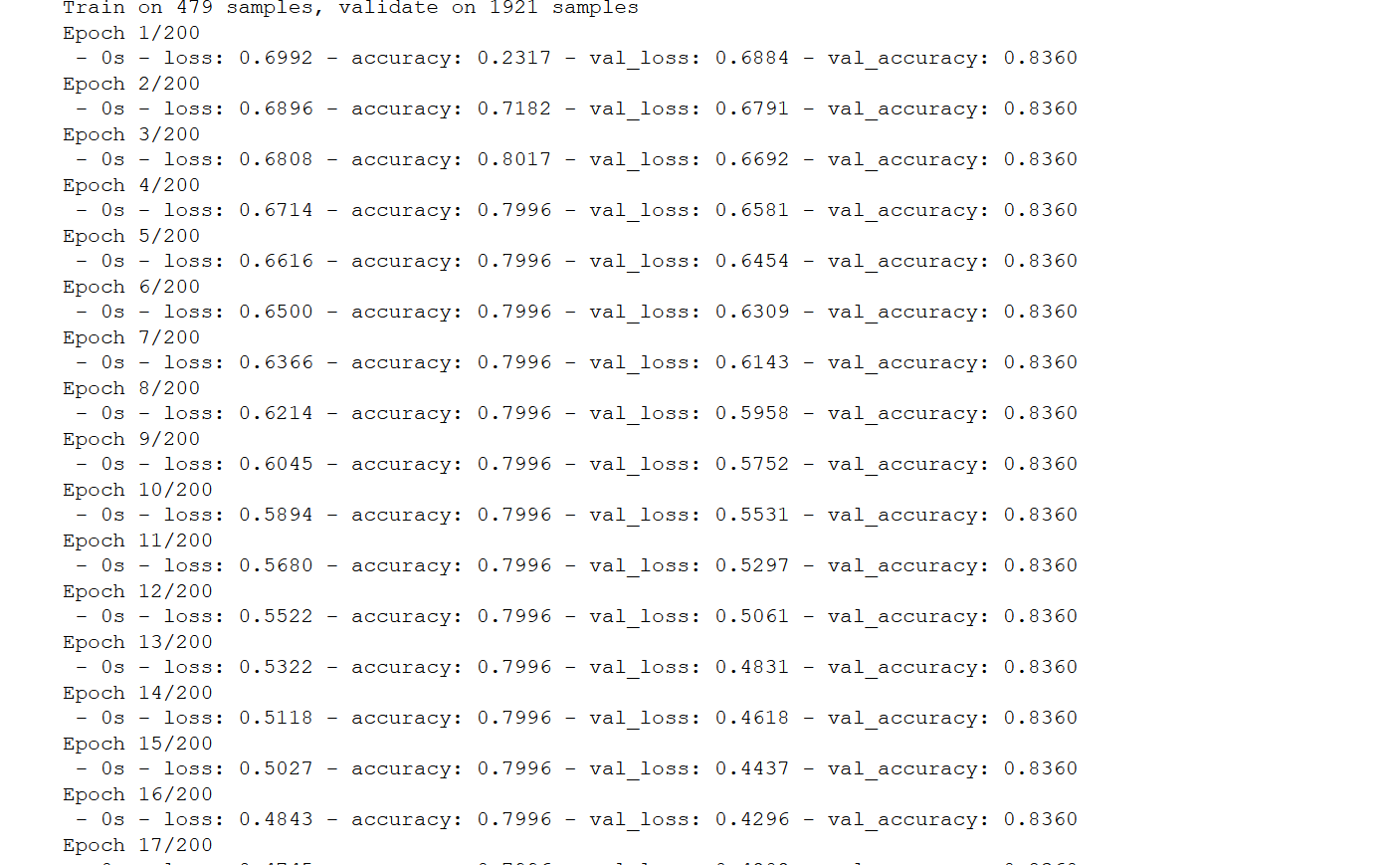
Fraud Detection using Keras

Keras: multi-label classification with ImageDataGenerator

Custom Data Augmentation in Keras

Custom Data Augmentation in Keras

ImportError: cannot import name 'normalize_data_format' · Issue #298 · keras-team/keras-contrib ...
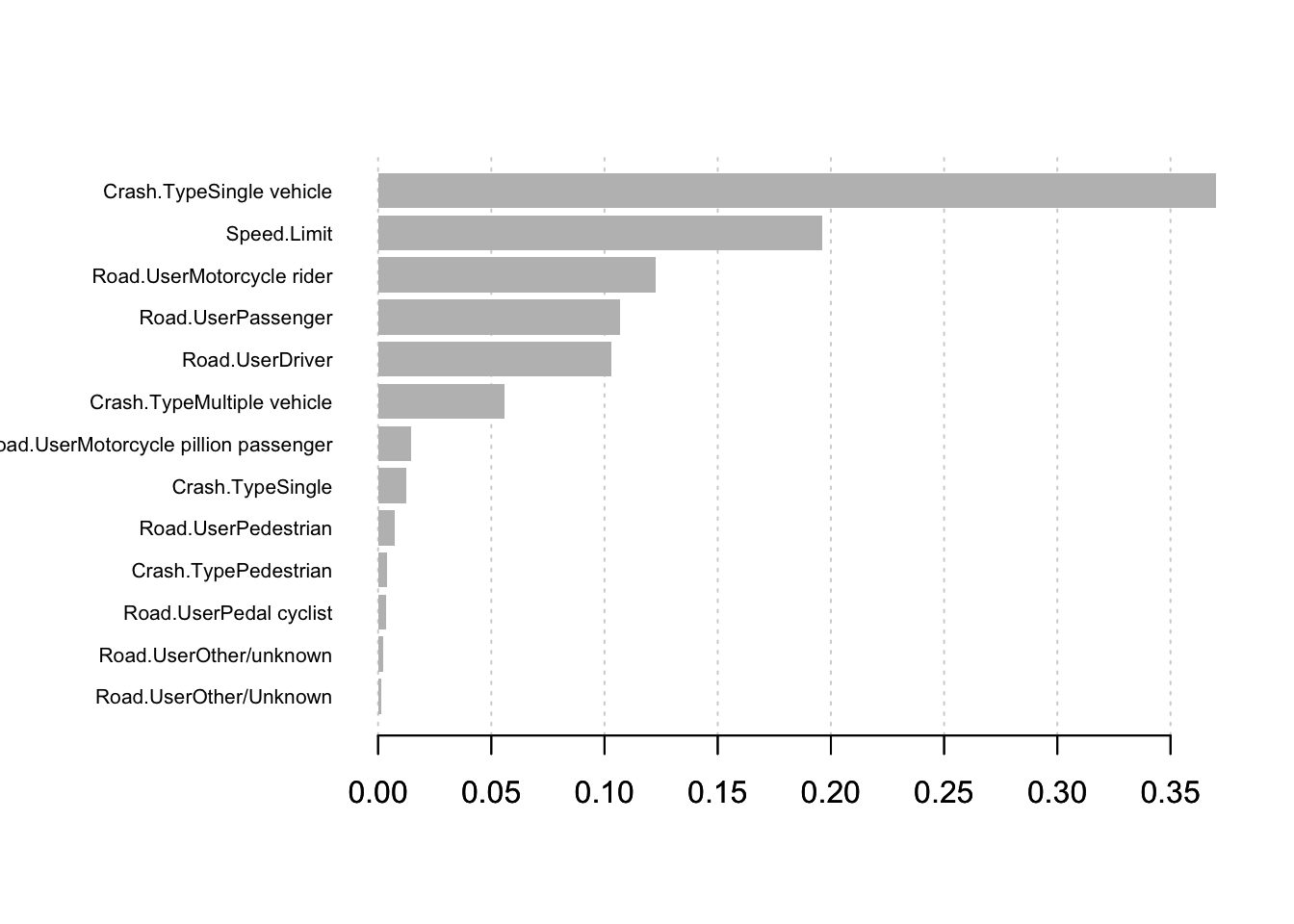
My top 10 R packages for data analytics - My top 10 R packages for data analytics | Actuaries ...
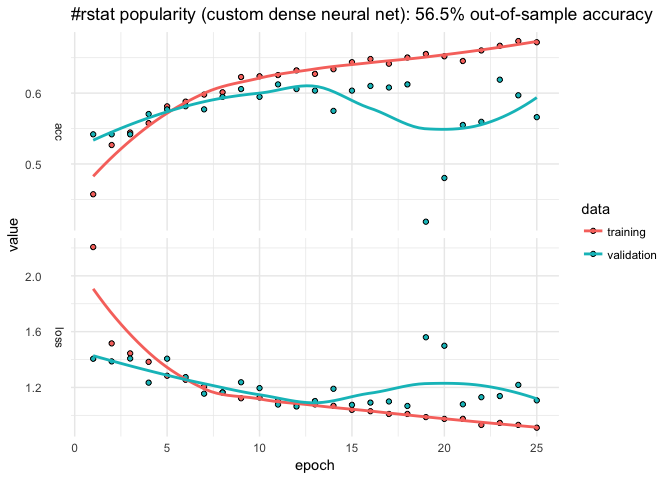
RStudio AI Blog: Analyzing rtweet Data with kerasformula
![[Get 38+] Image Generator Keras Flow](https://pyimagesearch.com/wp-content/uploads/2019/07/keras_data_augmentation_jitter.png)
[Get 38+] Image Generator Keras Flow
Post a Comment for "44 keras reuters dataset labels"